
Merhaba, bu yazıda araştırma sonuçlarını değerlendirirken sıkça gözden kaçırılan confounding ve bias kavramlarını ve bunların sonuçları nasıl yanıltabileceğini ele alacağız. Sayıların arkasındaki gerçek hikâyeyi birlikte sorgulayacağımız bu yazıda, keyifli okumalar dilerim.
Bir araştırmanın sonucuna bakarken genellikle istatistiksel anlamlılığa odaklanırız; oysa P değeri “anlamlı” ama sonuç yanlış olabilir. Çoğu zaman istatistik kusursuz bir şekilde doğru hesaplanmış olabilir ama veri, nedensel mekanizmaları göz ardı ettiği için aslında tamamen yanlış soruyu cevaplıyor olabilir. “Confounding” (karıştırıcı faktörler) veya farklı önyargı (bias) türleri, veriler arasındaki ilişkiyi çarpıtarak bizi gerçek dışı sonuçlara yönlendirebilir.1,2 Bu yüzden analizlerde sayıların arkasındaki nedensel hikayeyi sorgulamak zorundayız; çünkü “P değeri size doğruluğu değil, sadece tutarlılığı söyler”.
Confounding Nedir?
Confounding (karıştırıcı etki) en sade haliyle, incelediğimiz maruziyet (exposure) ile sonuç (outcome) arasındaki ilişkiyi çarpıtan üçüncü bir değişkenin (third variable) yarattığı istatistiksel bir yanılsamadır.2,3 Bir faktörün “confounder” kabul edilebilmesi için hem maruziyetle hem de sonuçla doğrudan ilişkili olması, ancak bu ikisi arasındaki nedensel zincirde (causal pathway) bir aracı olarak yer almaması şarttır.4 Bu üçlü ilişkiyi klasikleşmiş kahve ve akciğer kanseri örneğiyle çok net görebiliriz: 1980 ve 1990’larda yapılan çalışmalar kahvenin akciğer kanseri riskini artırdığını gösteriyordu, ama bu çalışmalarda kahve içenlerin aynı zamanda daha çok sigara içtiği gerçeği gözden kaçırılmıştı. İstatistiksel analizlerde sigara faktörü kontrol edildikten sonra, kahve ile kanser arasında aslında hiçbir ilişki kalmadığı ortaya çıktı. Yani kanser riskini artıran asıl sorun kahve değil, sigaraydı. Bu olay, nedensel zincirde yer almayan bir üçüncü değişkenin nedensel çıkarımları nasıl saptırabildiğini gösteren klasik ve mükemmel bir confounding örneğidir.
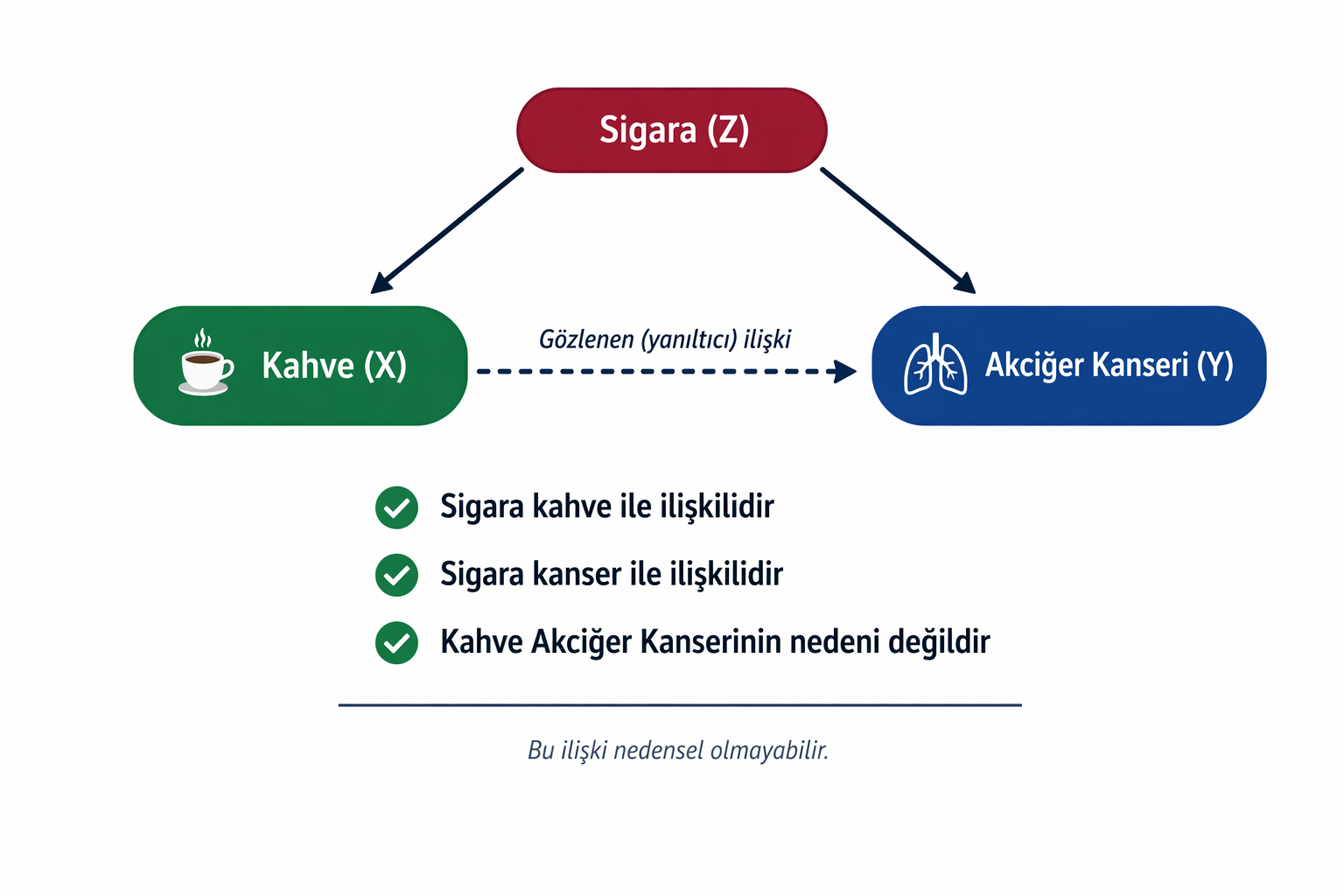
Kahve-sigara örneğinde gördüğümüz gibi confounding, incelediğimiz değişkenler arasındaki ilişkiye dışarıdan sızan bir ‘ortak neden’ (common cause) sorunudur ve doğru tespit edildiğinde istatistiksel olarak düzeltilebilir. Ancak araştırmalardaki her yanılsama doğadan veya dış faktörlerden kaynaklanmaz; bazen sorun araştırmacının yöntemindedir. Hastaları çalışmaya nasıl dâhil ettiğimiz, verileri nasıl ölçtüğümüz veya ‘karıştırıcıları kontrol edelim’ derken yanlış değişkenleri modele eklememiz, verinin yapısını kökünden bozabilir.
Bias Nedir?
Bias (yanlılık), verilerdeki rastgele olmayan, yapısal ve sistematik hatalardır. 3Bu hataların en sinsi ve tehlikeli özelliği, örneklem boyutunu ne kadar artırırsanız artırın (isterseniz sonsuz bir veri setiniz olsun) hiçbir zaman ortadan kaybolmamalarıdır. Çalışmanın tasarımına, hasta seçimine veya ölçüm kalitesine en başından nüfuz eden bu kusurlar, sonradan istatistiksel algoritmalar veya p-değerleriyle düzeltilemezler. Farkında olmadan yaptığımız bu hatalar, incelediğimiz tedavi ile sonuç arasındaki gerçek ilişkiyi tamamen maskeleyebilir, yapay olarak abartabilir veya daha da kötüsü, sonucu 180 derece tersine çevirecek kadar yıkıcı bir yanılsamaya yol açabilir.5,6
Selection Bias
Selection bias, analize dahil edilen bireylerin seçilme prosedüründen kaynaklanan bir yanılsamadır ve genellikle bir “ortak sonuca” (collider) göre veriyi kısıtladığımızda ortaya çıkar.
Obezite Paradoksu: Genel popülasyonda obezite, ölüm riskini doğrudan artıran bir faktördür. Ancak çalışma popülasyonunu sadece diyabet hastalarıyla kısıtlarsanız, obezitenin ölüm riskini azalttığı (sanki koruyucu bir faktörmüş gibi) tamamen paradoksal ve hatalı bir istatistiksel sonuçla karşılaşırsınız. Neden olur? Obezite normalde ölüm riskini artırır. Ancak sadece diyabet hastalarına bakarsanız, obezlerin daha az öldüğü gibi yanlış bir sonuç çıkabilir. Çünkü diyabet hem obezite hem de sigara gibi başka risklerle oluşur. Diyabetli ama obez olmayan kişiler genelde daha çok sigara içen, yani daha riskli hastalardır. Bu yüzden obezler daha sağlıklı görünür, ama bu gerçek değil, bir seçim yanlılığıdır.5
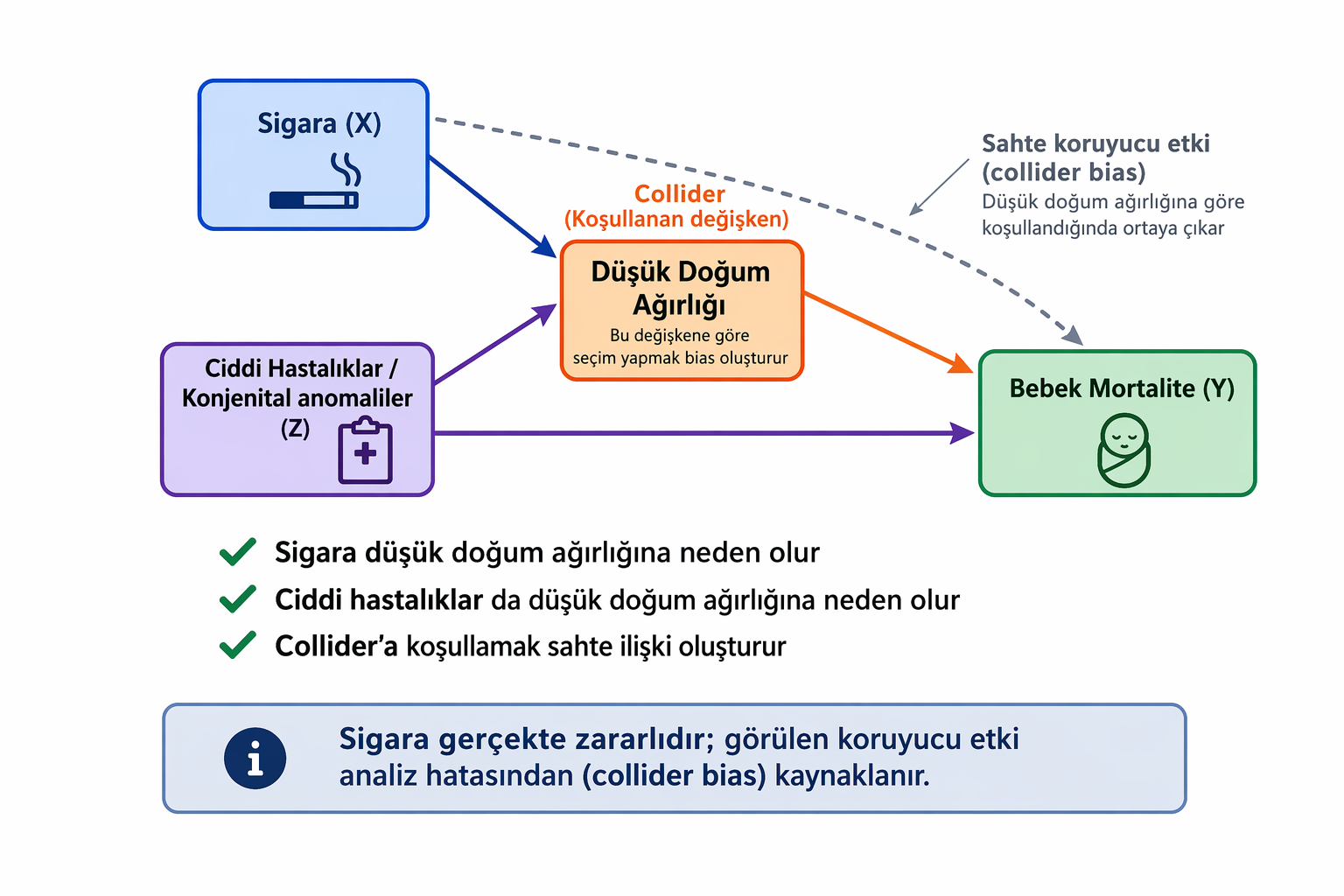
Doğum Ağırlığı Paradoksu: 1960’larda fark edilen bu duruma göre, sigara içen annelerin bebekleri ortalamada daha düşük kilolu doğsa da, çalışma sadece düşük doğum ağırlıklı bebekler ile kısıtlandığında; sigara içen annelerin bebeklerinin hayatta kalma oranının, sigara içmeyen annelerin bebeklerinden daha yüksek olduğu görülmüştür. Neden olur? Sigara içen annelerin bebekleri genelde daha düşük kilolu doğar ve bu aslında risklidir. Ancak sadece düşük doğum ağırlıklı bebeklere bakarsanız, sigara içen annelerin bebekleri daha iyi yaşıyor gibi görünebilir. Bunun nedeni, düşük doğum ağırlığının tek başına sigaradan değil, bazı çok ciddi hastalıklardan da kaynaklanabilmesidir. Sigara içmeyen annelerin düşük kilolu bebeklerinde bu ağır hastalıklar daha sık olabilir. Bu yüzden sigara zararlı olduğu halde, analiz yanlış yapıldığında koruyucu gibi görünür.7
Berkson Paradoksu (Hastaneye Yatış Yanlılığı): Acil Servis’e başvuranlar arasında sadece yoğun bakıma yatırılan hastaları analize dahil ederseniz, hastaneye yatma veya ağır durum kriterleri üzerinden kısıtlama yaptığınız için aslında birbiriyle ilgisiz iki hastalık veya faktör arasında sahte bir ilişki (Berkson paradoksu) bulursunuz. Neden olur? Genelde iki hastalık arasında bir ilişki olmayabilir. Ancak sadece yoğun bakım hastalarına bakarsanız, aslında ilgisiz iki durum birbiriyle ilişkili gibi görünebilir. Çünkü yoğun bakım ünitesine yatış, her iki hastalığın da ortak sonucudur; yani ağır olan hastalar zaten seçilmiş olur. Bu durumda bir hastalığı olanlarda diğerinin daha sık görülmesi, gerçek bir neden-sonuç ilişkisi değil, seçim yanlılığıdır. Yani analiz sadece yoğun bakım ünitesi hastalarıyla sınırlı olduğunda, yanlış ve yanıltıcı sonuçlar ortaya çıkar.7
Takibi Bırakma ve Kayıp Veri Yanlılığı (Differential Loss to Follow-up): HIV hastalarında yeni bir antiretroviral tedavinin 3 yıllık ölüm riski üzerindeki etkisini inceleyen klinik bir çalışma düşünün. Tedavi grubundaki bazı hastalar şiddetli yan etkiler nedeniyle çalışmayı (takibi) bırakır; öte yandan tedavi almayan grupta, ağır bağışıklık yetmezliği olan hastalar da semptomları çok ağırlaştığı için çalışmayı bırakır. Neden olur? Bir çalışmada sadece takibi tamamlayan hastalara bakmak yanıltıcı olabilir. Tedavi grubunda bazı hastalar yan etkiler yüzünden çalışmadan ayrılır, kontrol grubunda ise durumu ağır olanlar takibi bırakır. Yani çalışmada kalmak, hem tedaviden hem de hastalığın şiddetinden etkilenir. Bu yüzden geriye kalan grup gerçeği temsil etmez. Sonuçta tedavi olduğundan daha iyi ya da daha kötü görünebilir; bu da bir kayıp veri yanlılığıdır.3
Vaka-Kontrol Çalışmalarında Hatalı Kontrol Seçimi:Postmenopozal östrojen tedavisinin koroner kalp hastalığı üzerindeki etkisini araştıran bir vaka-kontrol çalışması planladığınızı düşünün. Kalp hastalığı olan vakaları seçtiniz, ancak kontrol grubunu (kalp hastalığı olmayanları) hastanedeki kalça kırığı olan kadınlar arasından seçmeye karar verdiniz. Neden olur? Östrojen kullanımının kemikleri güçlendirerek kalça kırığını önleyici bir etkisi vardır. Dolayısıyla, kontrol grubunu kalça kırığı olan hastalarla kısıtlamak, bu grupta östrojen kullananların sayısının genel popülasyona göre yapay olarak çok düşük çıkmasına neden olur. Bu kısıtlama, östrojenin kalp hastalığı riskini artırdığına dair gerçeği yansıtmayan, tamamen kontrol grubunun hatalı seçilmesine bağlı bir bias (yanlılık) ortaya çıkarır.3
Information Bias
Information bias, çalışma verilerindeki değişkenlerin kusurlu ölçülmesinden veya yanlış sınıflandırılmasından kaynaklanan sistematik ölçüm hatalarıdır,. Özellikle geriye dönük klinik çalışmalarda, hastaların geçmiş durumlarını veya maruziyetlerini, şu anki hastalık durumlarını bilerek yanlış veya eksik hatırlamasıyla oluşan “recall bias” (hatırlama yanlılığı) bunun en bilinen örneğidir. Bu tür ölçüm hataları, verideki gerçek ilişkiyi sulandırarak bizi nedensel olarak tamamen yanlış bir yola sürükler.3
Hatırlama Yanlılığı (Recall Bias): Geçmişe yönelik veri toplanan çalışmalarda, hastanın mevcut durumunun geçmişi hatırlama şeklini değiştirmesiyle ortaya çıkar. Örneğin, bebeklerinde doğumsal anomali olan anneler, sağlıklı bebek doğuran annelere kıyasla hamilelik dönemindeki alkol veya ilaç kullanımlarını çok daha detaylı ve abartılı hatırlama eğilimindedir. Benzer şekilde, demans teşhisi konmuş hastaların geçmişteki ilaç kullanımlarını eksik hatırlaması da maruziyetin hatalı ölçülmesine yol açar. Sonucun kendisi maruziyetin ölçümünü bozduğu için, tedavi ile hastalık arasında gerçekte olmayan sahte bir istatistiksel bağ doğar.3
Farklılaşmış Gözlem Yanlılığı (Differential Detection/Ascertainment Bias): Bu yanlılık, maruziyet durumunun (örneğin bir ilacı kullanıyor olmanın), sonucun ne kadar dikkatli ölçüleceğini doğrudan etkilemesiyle oluşur. Örneğin, belirli bir ilacın karaciğer toksisitesi yapabileceğinden şüphelenen doktorlar, bu ilacı alan hastaları diğer hastalara göre çok daha sıkı ve detaylı testlerle takip edebilirler. Bu durumda, ilacı kullanan grupta karaciğer sorunları çok daha erken ve sık teşhis edilirken, kullanmayan gruptaki hastaların sorunları gözden kaçar. Ölçüm eforundaki bu sistematik fark, ilacın zararını yapay olarak abartan bir bilgi yanlılığı yaratır.3
Ölçüm Zamanlamasına Bağlı Yanlılık (Reverse Causation Bias):Bazen ölçümün yapıldığı zamanlama, hastalığın kendisinin maruziyet ölçümünü bozmasına neden olur. Örneğin, bir ilacın karaciğer üzerindeki etkisini araştırırken, ilacın kullanım miktarını belirlemek için hastanın kanındaki ilaç seviyesinin karaciğer toksisitesi oluştuktan sonra ölçülmesi bu duruma mükemmel bir örnektir. Karaciğerin hasar görmüş olması zaten ilacın kandaki metabolizmasını ve seviyesini doğrudan değiştirecektir. Hastalığın kendisi ölçüm aracını bozduğu için, elde edilen verilerle yapılan analizler bizi tamamen yanlış bir nedensel çıkarıma sürükler.3
Confounding vs Bias Farkı
Confounding ve bias genellikle aynı şeymiş gibi düşünülse de aralarındaki en büyük fark “düzeltilebilirlik” potansiyelleridir. Confounding faktörleri çalışmada doğru bir şekilde tespit edilip ölçülebilir ve istatistiksel yöntemlerle analiz aşamasında kontrol edilerek düzeltilebilir,. Buna karşılık, selection veya information bias çalışmanın en başındaki tasarımına, hasta seçimine veya ölçüm kalitesine o kadar derinden işlemiştir ki, sonradan istatistiksel olarak geriye dönüp düzeltilmeleri çoğu zaman imkansızdır.
Peki nasıl düzeltiriz?
Randomizasyon
Randomizasyon, bir çalışmada maruziyetin veya tedavinin şansa bağlı rastgele bir mekanizmayla atanması işlemidir. Bu yöntem, hem ölçülebilen hem de ölçülemeyen tüm karıştırıcı faktörlerin etkisini ortadan kaldırarak tedavi ve kontrol gruplarını birbiriyle değiş tokuş edilebilir (exchangeable) hale getirir. Nedensel çıkarım yaparken seçim yanlılığını ve karıştırıcı etkiyi en başından önlediği için nedensellik kurmada altın standart ve en güvenilir yöntem olarak kabul edilir.1,3
Yeni bir tedavi yöntemi için yapılan bir kalp nakli çalışmasını düşünün. Kalp naklini sadece durumu en ağır ve kritik olan hastalara yaparsanız, “hastalığın şiddeti” güçlü bir karıştırıcı faktör (confounder) olarak devreye girer ve ameliyat olan gruptaki ölüm oranının yüksekliği sanki tedavinin zararlı olmasından kaynaklanıyormuş gibi yanıltıcı bir sonuç doğurur. Ancak hastaları nakil veya standart tıbbi tedavi grubuna dışarıdan hiçbir müdahale olmadan, sadece bir yazı-tura atışı gibi rastgele bir mekanizmayla atarsanız, durumu ağır olan ve olmayan hastalar her iki gruba da eşit şansla dağılır. Bu rastgele atama sayesinde tedavi ve kontrol grupları birbiriyle tamamen değiş tokuş edilebilir hale gelir ve ölçülebilen veya ölçülemeyen (örneğin hastaların başlangıçtaki gizli riskleri) tüm karıştırıcı faktörlerin etkisi tamamen ortadan kalkar.3
Stratification (Tabakalandırma)
Stratification, çalışma popülasyonunu incelemek istenen karıştırıcı bir değişkenin seviyelerine göre homojen alt gruplara (tabakalara) ayırarak analiz etme yöntemidir. Bu sayede, belirli bir değişkenin her bir tabakası içinde tedavi ve kontrol grupları arasında koşullu değiş tokuş edilebilirlik (conditional exchangeability) sağlanmış olur ve karıştırıcı etki izole edilir. Popülasyonun genelindeki ortalama nedensel etkiyi bulmak için, her bir alt gruptan elde edilen bu spesifik sonuçların ağırlıklı ortalaması alınır.3
Sigara (sigaraya karşı puro/pipo) kullanımı ile ölüm oranları arasındaki ilişkiyi inceleyen klasik bir çalışmayı düşünelim. Pipo ve puro genellikle daha yaşlı bireyler tarafından tüketildiği için “yaş” değişkeni burada güçlü bir karıştırıcı faktör (confounder) olarak karşımıza çıkar ve veriye bütün olarak bakıldığında yanıltıcı ölüm oranları doğurabilir. Bu karıştırıcı etkiyi düzeltmek için çalışma popülasyonu “20-40 yaş”, “41-70 yaş” ve “71 yaş ve üzeri” gibi homojen yaş tabakalarına ayrılır ve bireyler sadece kendi yaş tabakaları (strata) içinde birbiriyle karşılaştırılır. Analizin sonunda, popülasyonun geneli için ortalama nedensel etkiyi bulmak adına bu tabakalardan elde edilen oranların ağırlıklı ortalaması alınır ve böylece yaşın yarattığı karıştırıcı etki başarılı bir şekilde izole edilmiş olur.2,7
Multivariable regression (Çok Değişkenli Regresyon)
Çok değişkenli regresyon, tedavi ile sonuç arasındaki ilişkiyi etkileyen birden fazla karıştırıcı değişkeni (covariates) istatistiksel bir denklem içinde kontrol etmemizi sağlayan yaygın bir modelleme yöntemidir. Bu modeller, verilere belirli parametrik kısıtlamalar uygulayarak arka kapı yollarını (backdoor paths) kapatmayı ve nedensel etkiyi istatistiksel olarak izole etmeyi hedefler. Ancak regresyon modeline eklenecek değişkenlerin seçimi yalnızca veri algoritmalarına veya istatistiksel ilişkilere göre değil, değişkenler arasındaki nedensel yapıya (örneğin nedensel diyagramlara) dayanılarak yapılmalıdır.
Tiroid hastaları üzerinde yapılan klasik bir çalışmada, ham veriler sigara içenlerin içmeyenlere göre daha yüksek hayatta kalma oranına sahip olduğu gibi tamamen yanıltıcı bir sonuç ortaya koymuştur. Ancak nedensel bir diyagram (DAG) çizildiğinde, “yaş” değişkeninin hem sigara içme ihtimalini hem de ölüm riskini etkileyen bir confounder olarak açık bir arka kapı yolu yarattığı anlaşılır. Bu yanılsamayı düzeltmek için analiz körü körüne veri algoritmalarına bırakılamaz; “yaş” faktörü çok değişkenli regresyon modeline klinik ve nedensel bir kararla bilinçli olarak eklenmelidir. Yaş değişkeni regresyon denklemine dâhil edildiğinde bu arka kapı yolu matematiksel olarak kapanır ve sigaranın hayatta kalma üzerindeki gerçek (zararlı) etkisi başarılı bir şekilde izole edilmiş olur.2,8
“Regresyon modeline değişken eklemek sadece istatistik değil, klinik karardır.” Hangi değişkenin karıştırıcı (confounder), hangisinin aracı (mediator) veya ortak sonuç (collider) olduğunu sadece verilere ve istatistiksel p-değerlerine bakarak anlayamayız. Bu nedenle, modele bir değişken eklerken hastalığın biyolojisini, nedensel zincirini ve klinik işleyişi anlamak, herhangi bir algoritma çalıştırmaktan veya formül yazmaktan çok daha hayati bir adımdır.
Matching / Propensity score (Eşleştirme / Eğilim Skoru)
Eşleştirme (matching), tedavi gören bireyleri karıştırıcı özellikler açısından onlara en çok benzeyen tedavi görmemiş bireylerle eşleştirerek veri setinde yapay bir denge kurma işlemidir. Çok sayıda karıştırıcı değişkenin olduğu durumlarda, tüm bu ölçümler hastanın özelliklerine göre tedavi alma olasılığını yansıtan tek bir matematiksel değere, yani eğilim skoruna (propensity score) indirgenerek bu zorluk aşılabilir. Eğilim skoru üzerinden yapılan eşleştirme, ölçülen özellikler açısından tedavi ve kontrol gruplarının dağılımını eşitleyerek karıştırıcı etkiyi minimize eder.9
Yeni bir kolesterol ilacının kalp krizi riskine etkisini araştırdığınızı ve hastaların yaşı, tansiyonu, sigara kullanımı ve tıbbi geçmişi gibi çok sayıda confounder bulunduğunu düşünün. Bu kadar fazla değişkenle hastaları tek tek ve birebir eşleştirmek, veri seyrekleşeceğinden (curse of dimensionality) neredeyse imkansızdır. Ancak tüm bu özellikleri, o hastanın genel özelliklerine bakılarak “bu ilacı alma olasılığını” gösteren tek bir matematiksel değere, yani eğilim skoruna (propensity score) indirgeyebilirsiniz. Ardından, ilacı kullanan bir hastayı, onunla aynı veya çok benzer eğilim skoruna sahip ama ilacı almamış başka bir hastayla eşleştirerek, sanki hastalar en başından randomize bir klinik deneye dahil edilmiş gibi gruplar arasında mükemmel bir denge kurmuş olursunuz.9
Duyarlılık Analizi (Sensitivity Analysis):
Nedensellik literatürünün en güçlü kısımlarından biri Duyarlılık Analizi (Sensitivity Analysis) yaklaşımıdır. Geleneksel olarak araştırmacılar çoğunlukla “Çalışmada ölçülemeyen bir önyargı (bias) veya hata var mı?” diye sorup analizlerinin zayıflığından endişe duyarken, modern nedensellik bilimi“Bu önyargı ne kadar büyük olmalı ki bulduğumuz sonuç tamamen değişsin?” sorusuna odaklanır. Yani burada asıl felsefe, hatanın varlığını reddetmek veya ondan kaçmak değil, aksine alternatif nedensel ilişkilerin gücünü test ederek “bias’ı ölçmeye çalışmaktır”. Farklı senaryolar altında beklenen maksimum önyargının miktarını tahmin etmek, analizi sadece algoritmalara dayalı bir işlem olmaktan çıkarır. Bu sayede, elde edilen istatistiksel sonucun mantıklı bir bias ile yıkılıp yıkılamayacağını son derece şeffaf ve bilimsel bir şekilde sınamış oluruz.2,7
Bunu akciğer kanseri ve sigara ilişkisini çürütmek için öne sürülen “ikisini de etkileyen ölçülemeyen bir genetik confounder olabilir” şüphesi üzerinden örneklendirebiliriz. Araştırmacılar, bu görünmez karıştırıcının dağılımı ve etki gücü hakkındaki varsayımları adım adım değiştirerek Odds Ratio’nun (OR) veya nedensel etki tahminlerinin bundan nasıl etkilendiğini hesaplarlar. Bu ölçülemeyen karıştırıcıya dair varsayımlar değiştikçe elde edilen OR dalgalanır; ancak araştırmacılar bu sayede, sigaranın etkisini sıfırlayacak kadar devasa bir karıştırıcının doğada bulunmasının biyolojik olarak ne kadar mantıksız olduğunu somut sayılarla kanıtlamış olurlar.3
Nedensellik Merdiveni (Ladder of Causation)
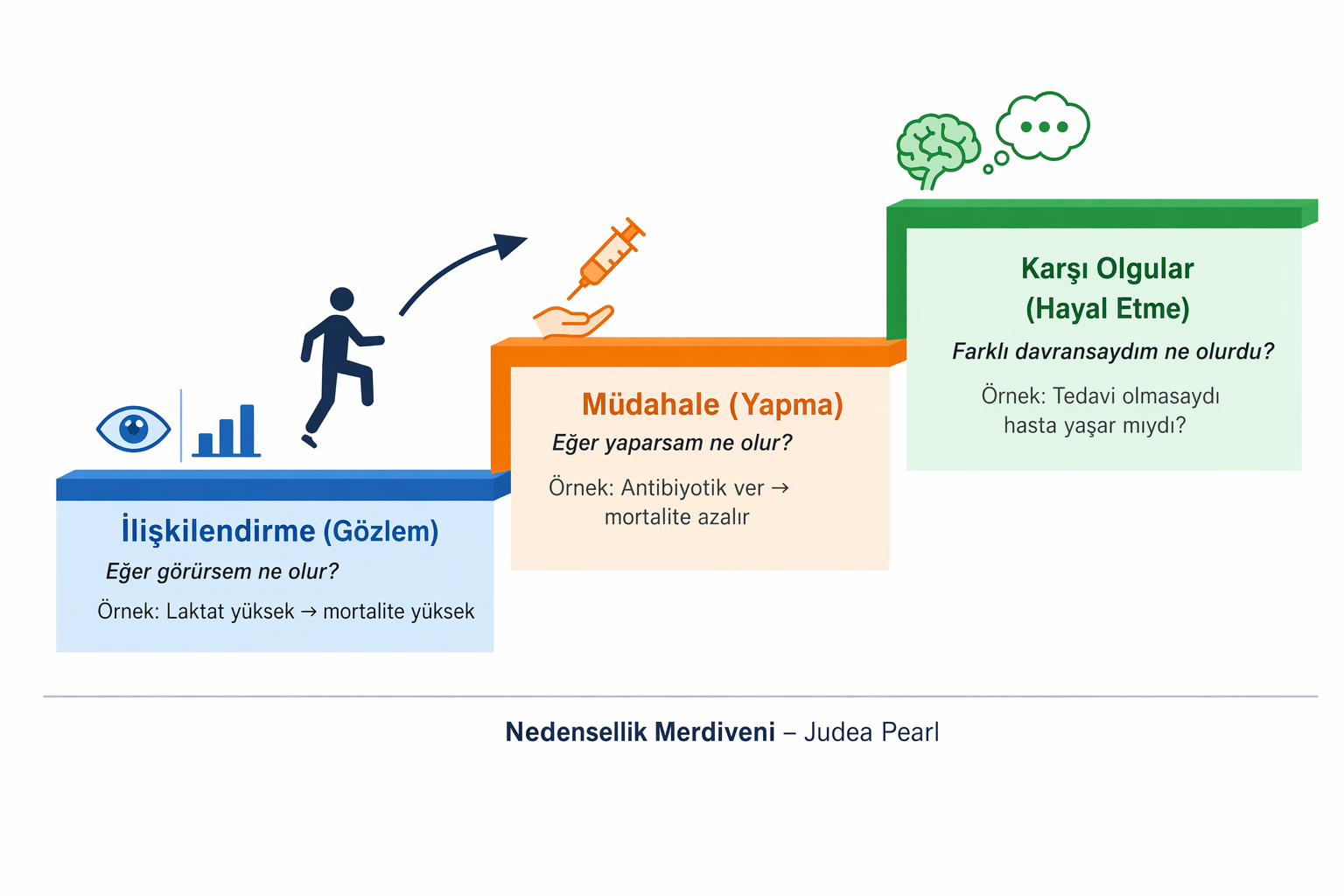
Judea Pearl’ün Nedensellik Merdiveni (Ladder of Causation), nedensel düşünme yeteneğimizi ve doğaya sorabileceğimiz soruların gücünü sınıflandıran üç temel bilişsel basamaktan oluşur. Bu metafor, sadece verileri işleyen makineler olmaktan çıkıp, etrafımızdaki dünyayı açıklayabilen varlıklara dönüşme sürecimizi haritalandırır. Merdivenin basamaklarını tıbbi örnekler üzerinden şu şekilde açıklayabiliriz:7
1. Basamak: İlişkilendirme (Association / Görme ve Gözlemleme)
En alt basamak olan ilişkilendirme, çevremizdeki düzenlilikleri pasif bir şekilde gözlemlemeye ve tespit etmeye dayanır. Bu basamağın temel sorusu “Eğer … görürsem ne olur?” şeklindedir. Çoğu hayvanın hayatta kalma güdüsü ve günümüzün en gelişmiş yapay zeka (derin öğrenme) algoritmaları bile hala tamamen bu basamakta çalışır. Örneğin, bir hastada belirli bir semptomu (örneğin, kronik öksürük) gözlemlediğimizde, o hastanın belirli bir hastalığa (örneğin, akciğer kanseri) sahip olma olasılığının ne olduğunu sadece eldeki devasa klinik verilere ve istatistiksel korelasyonlara bakarak bulabiliriz. Ancak bu basamaktaki istatistiksel analizler, ilişkinin nedensel yönünü; yani öksürüğün mü kansere, yoksa kanserin mi öksürüğe neden olduğunu veya her ikisine de yol açan ortak bir faktörün (örneğin sigara) mü bulunduğunu bize söyleyemez. Bu basamakta iyi tahminler yapmak için iyi açıklamalara ihtiyacımız yoktur.7
2. Basamak: Müdahale (Intervention / Yapma)
Bir üst basamağa çıktığımızda, acil serviste yalnızca gözlem yapmakla kalmaz, aynı zamanda hastanın seyrini aktif olarak değiştirmeye başlarız. Bu basamağın tanımlayıcı sorusu “Eğer … yaparsam ne olur?” (What if I do…?) veya “Nasıl yapabilirim?” şeklindedir. Örneğin, acil servise hipotansiyon ve taşikardi ile başvuran bir hastada sadece bu bulguların şokla ilişkili olduğunu gözlemlemekle yetinmeyiz; “Eğer bu hastaya hızlı sıvı resüsitasyonu başlarsam kan basıncı düzelir mi?” ya da “Erken vazopressör başlarsam mortaliteyi azaltabilir miyim?” gibi sorular sorarız. Benzer şekilde, solunum sıkıntısı olan bir hastada non-invaziv mekanik ventilasyon (NIV) başlamak, travma hastasında traneksamik asit (TXA) uygulamak veya sepsis düşündüğümüz bir hastada erken antibiyotik vermek gibi müdahalelerle hastalığın doğal seyrini değiştirmeyi hedefleriz.
Bu tür sorular, yalnızca gözlemsel verilerle doğrudan cevaplanamaz; çünkü bir müdahalenin gerçek etkisini anlayabilmek için o müdahalenin bilinçli olarak uygulanması ve sonuçlarının değerlendirilmesi gerekir. Bu nedenle randomize kontrollü çalışmalar gibi tasarımlar bu basamağın temelini oluşturur. Matematiksel olarak bu tür müdahaleler, dışarıdan yapılan bir eylemi temsil eden do-operatörü (do(X)) ile ifade edilir. Örneğin, do(antibiyotik) ya da do(NIV), yalnızca bu tedaviyi alan hastalarda ne olduğunu gözlemlemekten ziyade, “bu tedaviyi özellikle uygularsam ne olur?” sorusunu temsil eder. Bu basamak, klinik karar verme sürecinin merkezinde yer alır ve tedavi stratejilerinin etkinliğini anlamamızı sağlar.7
3. Basamak: Karşı Olgular (Counterfactuals / Hayal Etme ve Anlama)
Nedensellik merdiveninin en üst basamağı; geçmişe bakma, hayal etme ve derinlemesine anlamaya dayanır. Temel sorusu “Farklı davransaydım ne olurdu?” veya **”Neden?”**dir. Bu basamak, gerçekleşmiş olan gerçek dünyayı, hiç gerçekleşmemiş olan çelişkili (kurgusal) bir dünyayla karşılaştırmamızı gerektirir. Örneğin, acil serviste sepsis nedeniyle başvuran ve geç antibiyotik verilen bir hastanın kaybedildiğini düşünelim. Bu durumda asıl soru şudur: “Eğer bu hastaya ilk saat içinde antibiyotik verilseydi sonuç değişir miydi?” Benzer şekilde, NIV başarısızlığı gelişen bir hastada “Başlangıçta invaziv ventilasyon tercih edilseydi prognoz daha iyi olur muydu?” ya da travma hastasında “Traneksamik asit daha erken verilseydi mortalite azalır mıydı?” gibi sorular, klinik pratiğin en kritik karar noktalarını oluşturur. Bu basamak, sadece “ne oldu?”yu değil, “neden oldu?”yu anlamaya çalışır ve gerçek anlamda klinik muhakemenin temelini oluşturur.7
Özet
Araştırma sonuçlarını değerlendirirken yalnızca istatistiksel anlamlılığa odaklanmak, bizi en sık yapılan hatalardan birine sürükler: ilişkiyi nedensellik sanmak. Oysa bu yazıda gördüğümüz gibi, confounding ve farklı bias türleri, tamamen ilgisiz değişkenleri ilişkili gösterebilir, gerçek etkileri maskeleyebilir ya da sonuçları tersine çevirebilir. Üstelik bu hatalar, örneklem büyüklüğü artsa bile ortadan kalkmaz; aksine daha ikna edici hale gelebilir.
Bu nedenle bir çalışmayı değerlendirirken sadece “sonuç anlamlı mı?” sorusunu değil, “bu sonuç nasıl oluştu?” sorusunu da sormak gerekir. Çalışma popülasyonu nasıl seçildi? Hangi değişkenler ölçüldü, hangileri gözden kaçtı? Analiz, verinin arkasındaki nedensel yapıyı gerçekten yansıtıyor mu? Bu soruların cevabı, çoğu zaman p-değerinden daha değerlidir.
Nedensellik merdiveni bize şunu öğretir: iyi bir klinisyen veya araştırmacı olmak, yalnızca ilişkileri görmek değil; müdahaleyi anlamak ve alternatif senaryoları düşünebilmektir. Çünkü tıpta doğru karar, çoğu zaman gördüğümüz veriden değil, o verinin nasıl oluştuğunu anlayabilmekten doğar.
Sonuç olarak:
İstatistik bize ne kadar emin olduğumuzu söyler; ama neyin doğru olduğunu söylemez. Gerçeğe ulaşmak için sayıları değil, nedenselliği sorgulamak gerekir.
Referanslar
- 1.Pearly J, Glymour M, Jewell NP. Causal Inference in Statistics: A Primer. Wiley; 2016.
- 2.Pearly J. Causality. Cambridge University Press; 2009.
- 3.Hernan MA. Causal Inference: What If. Taylor & Francis; 2024.
- 4.Weinberg CR. Toward a Clearer Definition of Confounding. American Journal of Epidemiology. Published online January 1, 1993:1-8. doi:10.1093/oxfordjournals.aje.a116591
- 5.Tönnies T, Kahl S, Kuss O. Collider Bias in Observational Studies. Dtsch Arztebl Int. 2022;119(7):107-122. doi:10.3238/arztebl.m2022.0076
- 6.Schisterman EF, Cole SR, Platt RW. Overadjustment Bias and Unnecessary Adjustment in Epidemiologic Studies. Epidemiology. Published online July 2009:488-495. doi:10.1097/ede.0b013e3181a819a1
- 7.Goldberg LR. The Book of Why: The New Science of Cause and Effect. Quantitative Finance. Published online October 1, 2019:1945-1949. doi:10.1080/14697688.2019.1655928
- 8.Shrier I, Platt R. Reducing bias through directed acyclic graphs. BMC Med Res Methodol. 2008;8:70. doi:10.1186/1471-2288-8-70
- 9.Cunningham S. Causal Inference: The Mixtape. Yale University Press; 2021.